

ChatGPTは、「猫」と「犬」が近い言葉だと理解しています。
でも、AIは人間のように“意味”を感覚で理解しているわけではありません。
では、なぜAIは、
- 「猫」と「犬」は近い
- 「猫」と「自動車」は遠い
と判断できるのでしょうか?
実は、その裏側では「内積」という数学の計算が使われています。
高校数学では「ベクトルの計算」として登場する内積ですが、現代ではAI・検索・おすすめ機能など、さまざまな場面で活躍しています。
この記事では、
- 内積とは何を表しているのか?
- なぜAIで使われるのか?
- ChatGPTはどうやって“似た意味”を見つけているのか?
を、できるだけ直感的に解説していきます。
そもそも「内積」とは?
内積は、簡単に言えば、「2つのベクトルが、どれくらい同じ方向を向いているか」を表す計算です。
数式で書くと、こうなります。
$$\vec{a} \cdot \vec{b} = |\vec{a}| |\vec{b}| \cos\theta$$
ここで重要なのは、
- ベクトルの長さ:\(|\vec{a}|, |\vec{b}|\)
- ベクトル同士の角度:\(\theta\)
の2つです。
特にポイントなのが、\(\cos\theta\)。
\(\cos\theta\) は、
- ベクトルが同じ向き → \(1\) に近い
- ベクトルが直角 → \(0\)
- ベクトルが逆向き → \(-1\) に近い
という値になります。
ベクトルの角度が小さいほど、内積は大きくなる
そのため、内積(\(\vec{a} \cdot \vec{b} = |\vec{a}| |\vec{b}| \cos\theta\))には、
- 同じ方向 → 内積は大きい
- 直角 → 内積は \(0\)
- 逆方向 → 内積は負になる
という性質があります。
つまり、「向きが近いほど、内積は大きくなる」のです。
これが、AIにおける「類似度」の計算につながっています。
AIは言葉を「ベクトル」に変換している
ChatGPTのようなAIは、単語や文章をそのまま理解しているわけではありません。
まず、「単語」を大量の数字の並び(ベクトル)に変換しています。
たとえば、イメージとしてはこんな感じです。
| 単語 | ベクトル(イメージ) |
|---|---|
| 猫 | (0.8, 0.7, 0.2, …) |
| 犬 | (0.7, 0.6, 0.3, …) |
| 自動車 | (-0.2, 0.1, 0.9, …) |
実際には数百〜数千次元ありますが、重要なのは、「意味が近い単語ほど、近い方向のベクトルになる」ということです。
AIの中では、単語は「意味空間」と呼ばれる空間に配置されています。
意味が近い単語ほど、近い場所に並ぶイメージです。
AIは、大量の文章を学習する中で、
- よく似た場面で使われる単語
- 似た文脈で登場する単語
を、自然と近い方向に配置するようになります。
だから「猫」と「犬」は近くなる
AIの中では、
- 猫
- 犬
は似た文脈で使われることが多いため、ベクトルの向きも近くなります。
一方で、
- 猫
- 自動車
は使われる場面がかなり違うので、方向も離れます。
すると、
- 「猫」と「犬」の内積 → 大きい
- 「猫」と「自動車」の内積 → 小さい
となる。
つまりAIは、「内積が大きい = 意味が近い」として判断しているのです。
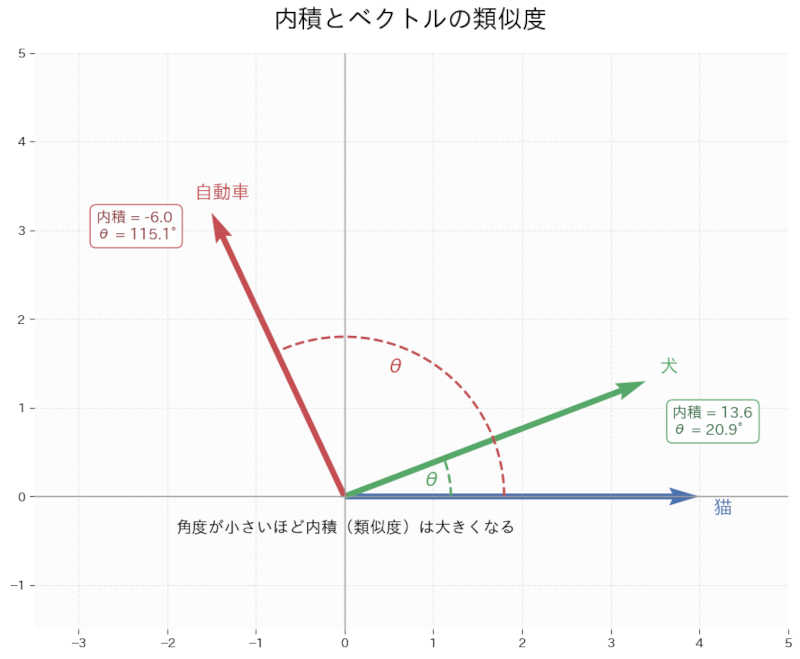
図で見るとこんなイメージ
「猫」と「犬」は角度が小さいため、内積(類似度)が大きくなっています。
一方で、「猫」と「自動車」は方向が離れているため、内積も小さくなります。
実際のAIでは「コサイン類似度」も使われる
実際のAIでは、「コサイン類似度(cosine similarity)」という形で、ベクトル同士の角度だけを取り出して比較することもあります。
これは、内積を「ベクトルの長さ」で割って正規化したものです。
数式で書くと、こうなります。
$$\cos\theta = \frac{\vec{a} \cdot \vec{b}}{|\vec{a}| |\vec{b}|} $$
これは、ベクトルの“長さ”ではなく、「方向の近さ」だけを見たいからです。
コサイン類似度は、
- \(1\) に近い → 方向が近い
- \(0\) に近い → 関係が薄い
- \(-1\) に近い → 逆方向
という意味になります。
たとえば、
- 文章の長さが違っても
- 単語数が違っても
「意味の近さ」を比較しやすくなる。
そのため、検索エンジンやベクトル検索、生成AIなどでも広く使われています。
ChatGPTも「関連する知識」を探している
ChatGPTは質問を受け取ると、「この質問と意味が近い情報はどれか?」を内部で探しています。
このときにも、文章をベクトル化し、内積や類似度計算が使われています。
たとえば、
- 「おすすめのミステリー小説を教えて」
- 「どんでん返し系の小説が読みたい」
は、言葉が完全には一致していなくても、意味はかなり近い。
AIはそれを、ベクトル同士の近さとして判断しています。
こうした技術は、「埋め込み(embedding)」や「ベクトル検索」と呼ばれることもあります。
内積はAIの「重みづけ」にも使われる
内積は、単なる類似度計算だけではありません。
ニューラルネットワークでは、「どの特徴をどれくらい重視するか?」を計算するためにも使われています。
たとえばAIは、
- 耳がある
- しっぽがある
- 鳴く
といった特徴を数字として持っています。
そして、
- どの特徴を強く見るか?
- どの特徴をあまり重視しないか?
という「重み」をかけながら判断している。
この「特徴量 × 重み」の合計が、実は内積なのです。
つまり内積は、AIの「判断そのもの」に使われている計算とも言えます。
なぜ内積で“似ている”が分かるのか?
ここまで見てきたように、内積は、
- ベクトルの長さ
- ベクトルの向き
を同時に扱える計算です。
特に重要なのは、「向きが近いほど値が大きくなる」という性質。
だからAIでは、
- 意味が近い文章
- 関連する画像
- 好みが似ているユーザー
などを探すために、内積が広く使われています。
つまり内積は、AIにとって「意味の近さ」を測るための基本技術なのです。
まとめ
高校数学で学ぶ「内積」は、実はAIの世界でも重要な役割を持っています。
特に、
- 意味の近さ
- 類似度
- 重みづけ
を計算する場面で、内積は欠かせません。
ChatGPTが“それっぽい答え”を返せるのも、単語や文章をベクトルとして扱い、内積を使って近い情報を探しているからです。
教科書の中の数式だった「内積」は、今ではAIが“意味”を理解するための技術になっているのです。
そう考えると、内積が少し面白く見えてきませんか?
そう感じた人には、内積やベクトルを“意味”から解説してくれる本もおすすめです。

次に読むなら
「なぜ \(\cos\theta\) が出てくるの?」
「なぜ直角だと内積は \(0\) になるの?」
そんな“内積の本質”を、図解でわかりやすく解説したのがこちらです。



コメント